






Introducing Lift: self-improvement layer for your Voice AI Agent
June 29, 2026
|
4 min

Introducing multilingual voice AI agents that earn trust in India's vernacular languages
Every voice AI platform in India now lists a dozen Indian languages on its feature page.
However, when deployed in production, the pattern is the same: regional language campaigns see higher drop-off rates, shorter call durations, and lower conversion than Hinglish. Customers hear Tamil that sounds like a textbook, or Kannada that sounds like a newsreader, and disengage within seconds. Even though the language was available, the voice AI agent completely failed to build trust with the customer.
Trust, in a voice AI call, shows up as a set of specific behaviors. The customer stays on the call. They answer in full sentences. They engage instead of trying to end the conversation. They don't ask "am I speaking to a bot?"
We built a system to earn those behaviors across India's vernacular languages. The production data shows it works.
Launching voice AI agents that operate across India's vernacular languages, in production, at scale, in live enterprise campaigns.
English voice AI had a head start: large conversational training data, a small gap between written and spoken forms, one dominant dialect for most business contexts. Indian languages have none of this.
Written Tamil and spoken Tamil function as different languages. So do written Bengali and spoken Bengali, written Malayalam and spoken Malayalam. A text-to-speech model trained on read-speech corpora produces formal output that sounds foreign to a native speaker in Madurai, Kochi, or Bengaluru.
On top of that, real calls are multilingual by default: customers mix languages mid-sentence, dialect variation within a single language is enormous, and production-quality training data at 8kHz telephonic quality does not exist for most Indian languages.
Off-the-shelf speech recognition models, even those purpose-built for Indian languages, when used as is, struggle in these conditions. They misrecognize regional words, bleed transcription across languages when code-switching is heavy, and add latency that breaks conversations.
Getting recognition right for production telephonic audio is a solvable problem. You choose the right model, tune it for your domain, add custom vocabulary. However, making the voice sound like a real human is the harder problem.
.png)
We ran an experiment with our first Hinglish voice agents. Tuned the TTS settings: speed, volume, emotion, stability. Then tested that against a version with identical settings but hand-rewritten dialogue. The hand-written version generated better results by a wide margin, every time.

The finding: naturalness splits roughly 20/80 between TTS configuration and dialogue engineering. We hand-build the 80% and validate it on real phone calls. No model generates it.

These agents are live across enterprise campaigns in travel, lending, and marketplace verticals. One example: a multilingual feedback operation we run with redBus across Indian languages.
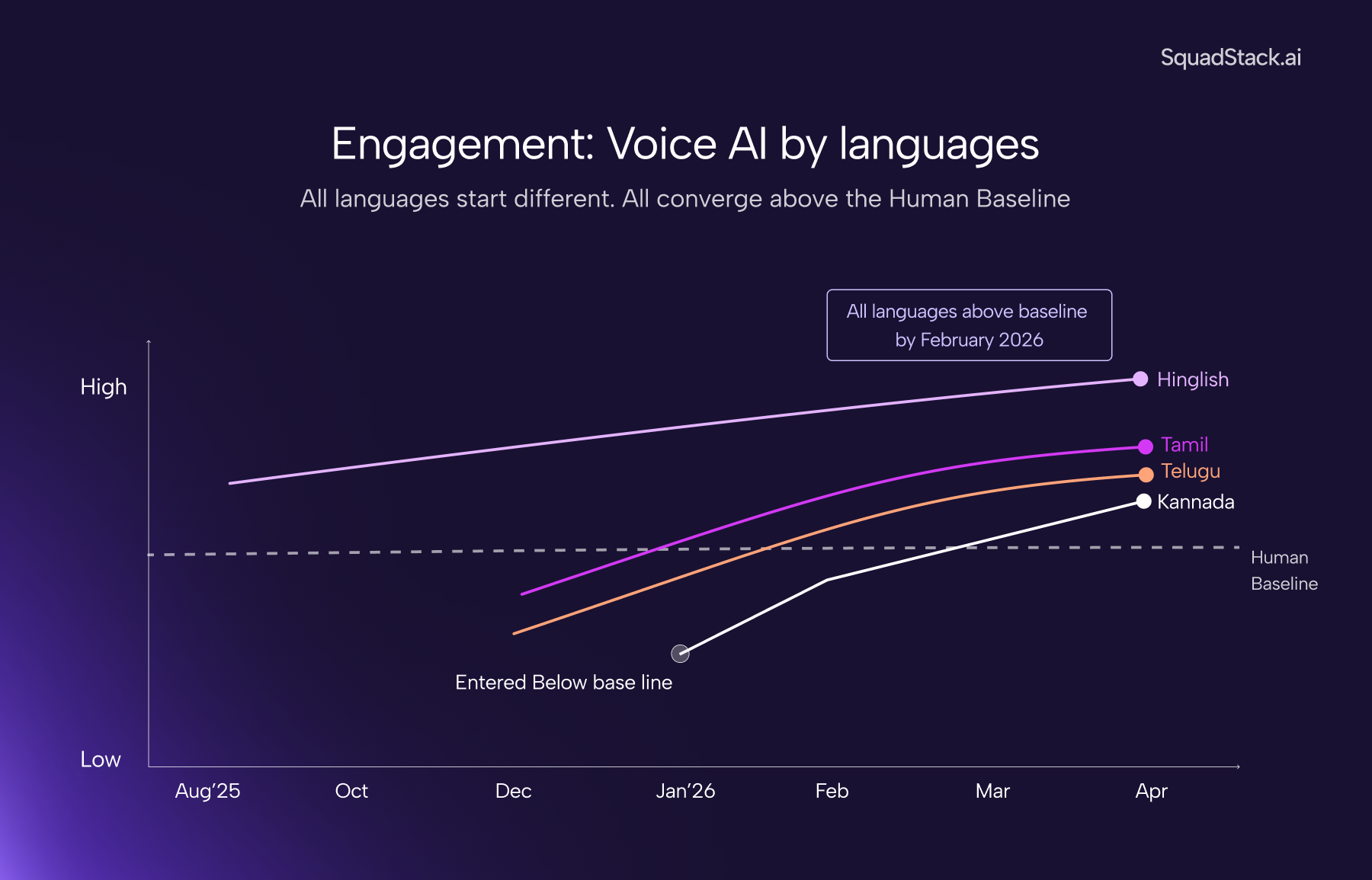
Every metric enterprises track in voice AI runs through the same variable: the customer's three-second judgment. Person, or machine.
Models will keep improving. Language counts will keep climbing. The craft layer, the dialogue engineering, the per-language speech artifacts, the voice-by-voice testing, the deliberate imperfections that make a machine sound human, stays manual. Stays specific.
Outcomes start there.


/
00:00
/
00:00
/
00:00
/
00:00
/
00:00
/
00:00
/
00:00
/
00:00
00:00
00:00
00:00
00:00
00:00
00:00
00:00
00:00



