






Why your voice AI leaks customer data on every sensitive call, and how we fixed it
July 9, 2026
|
4 minutes

SquadStack.ai's agents are indistinguishable from humans in naturalness and performance with 4× lower cost.
What is the Turing test and Why it Matters?
Alan Turing, the father of modern computer science, created the Turing test as a method for determining whether a machine can exhibit intelligent behavior which is indistinguishable from that of a human. The original test included a human judge engaging in a conversation with two anonymous participants: one human and one AI. If the judge cannot reliably tell which is which, the machine is said to have "passed" the Turing test.
Contact centers have been called out as the ultimate proving ground for AI applications for many years and passing the Turing test here is especially critical since enterprises heavily rely on contact centers for managing sales, customer support and customer experience.
We have spent the last five years building an AI-native contact center stack from the ground up. All that effort led us to finally cracking the Turing Test in September 2025. As an AI company at the application layer, passing the Turing Test means we finally know what a great product looks like in the GenAI era - and it’s only going to raise the bar from here.
This wasn’t an overnight discovery - it was all leading up to a tipping point.
Before the tipping point: AI is treated like a copilot, assistant, or junior intern. It’s helpful, but it still needs oversight. This is where most industries sit for a while - people experiment, augment workflows, and run hybrid setups.
After the tipping point: Once AI matches or beats humans at the core task, the conversation shifts from augmentation to automation. Budgets get reallocated. Entire workflows get redesigned. Adoption jumps exponentially instead of linearly.
.png)
Now we’ve crossed this tipping point and cracked the Turing Test using two methods.
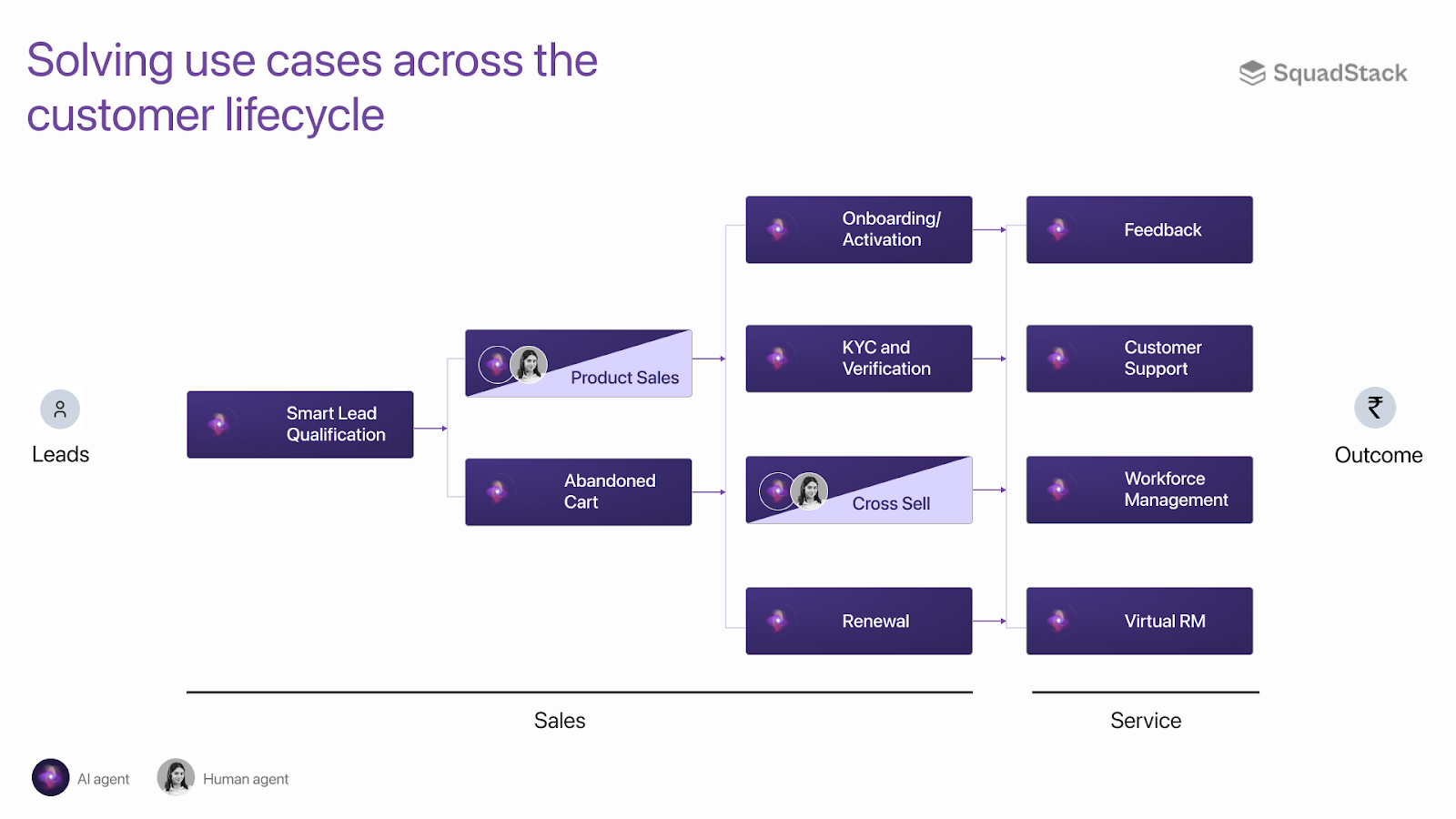
Some examples of how AI agents are now embedded in the important enterprise contact center workflows.
Each of these use cases demand nuance, persuasion, and trust-building - need AI agents to be truly indistinguishable from humans in outcomes.
There can be two methods of performing the Turing test for contact centers. (1) Blind listening test and (2) Functional test.

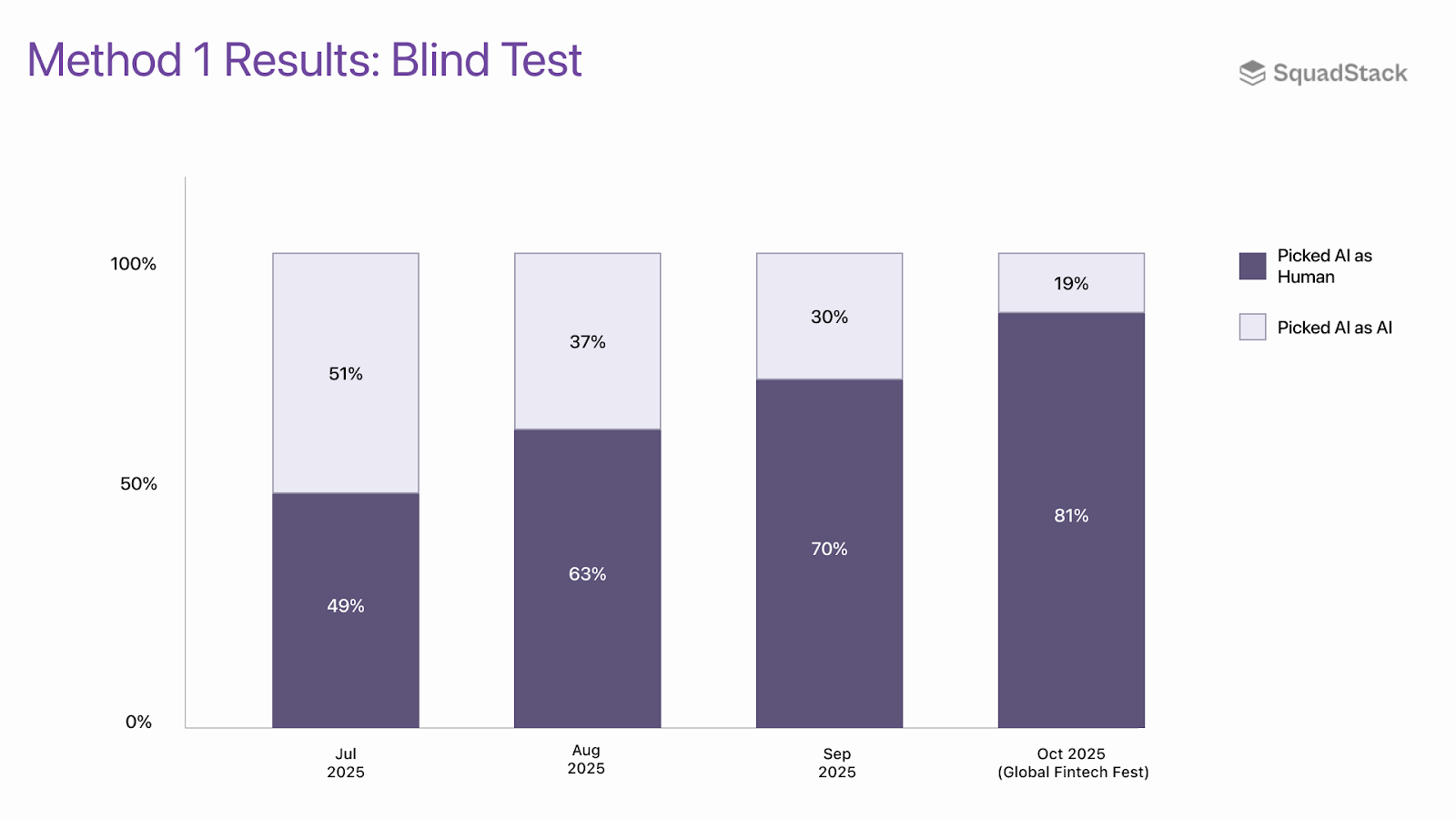
The traditional method - like the original test by Turing - a blind listening test with a mixed set of human and AI recordings. This method only evaluates the naturalness of the AI agent without any concrete judgment on real business outcomes.
We began live blind tests in July 2025, when AI agents started showing reasonable naturalness. Early results were close to a 50–50 coin toss. By September, the needle had moved: 352 of 503 listeners (70%) identifying at least 1 AI agent conversation as human.
In October 2025, we took the test to real scale at the Global Fintech Fest (GFF) - the world’s largest fintech summit, attended by BFSI leaders, technologists, and policymakers from around the globe. Over the 3 days of the event, 1563 attendees participated and 1273 (81%) identified our AI agents as human.
This is a very positive signal on naturalness, but it only tests perception. It determines little about real business outcomes or efficiencies demanded by contact centers.
For really claiming to pass the Turing test for contact center applications, indistinguishability needs to be achieved across the following parameters:
Naturalness is how close an AI agent is to conversing like a human contact center agent. This depends on the quality of voice, prosody, turn-taking, pronunciation, diction, and latency. However, these are subjective indicators that can be tested through blind listening (Method 1).
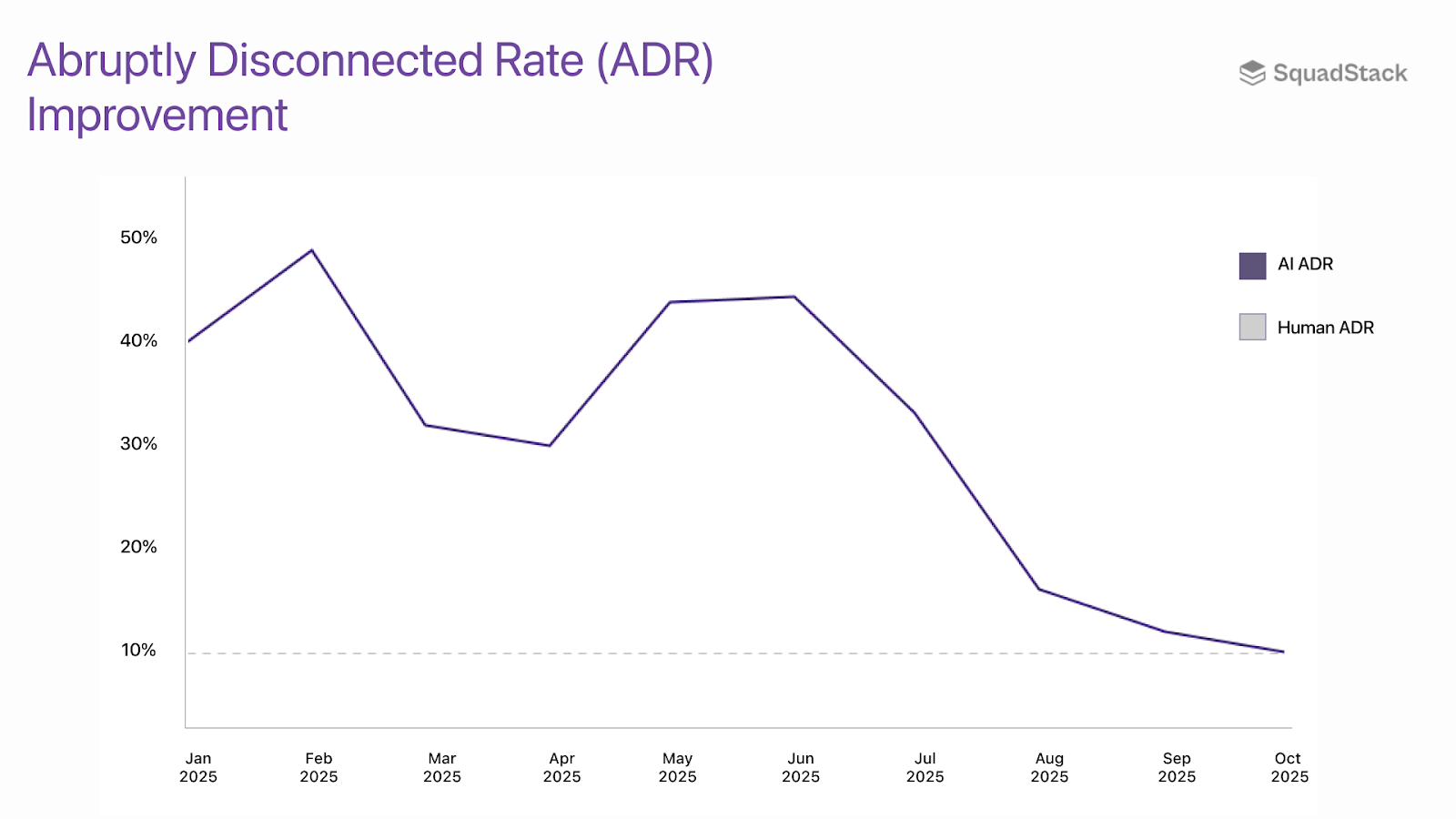
A quantitative and metric driven way to measure naturalness is the Abruptly Disconnected Rate (ADR). It tracks how many calls get cut off in the first 10 seconds right after being identified as a contact-center interaction. And it’s obvious why that matters - the moment a caller senses they’re talking to an AI instead of a human, they tend to hang up even more. A lower ADR means the agent sounds more natural and keeps people engaged, which is critical for passing the Turing Test in real-world conversations.
We’ve always benchmarked ADR for AI agents against human agents. Earlier automation like IVR menus and first-gen voice bots often had 70%+ ADR. As the stack improved, especially with generative AI agents, ADR has fallen sharply to around 10% for AI agents (8-12% is the standard range for human agent campaigns as well).
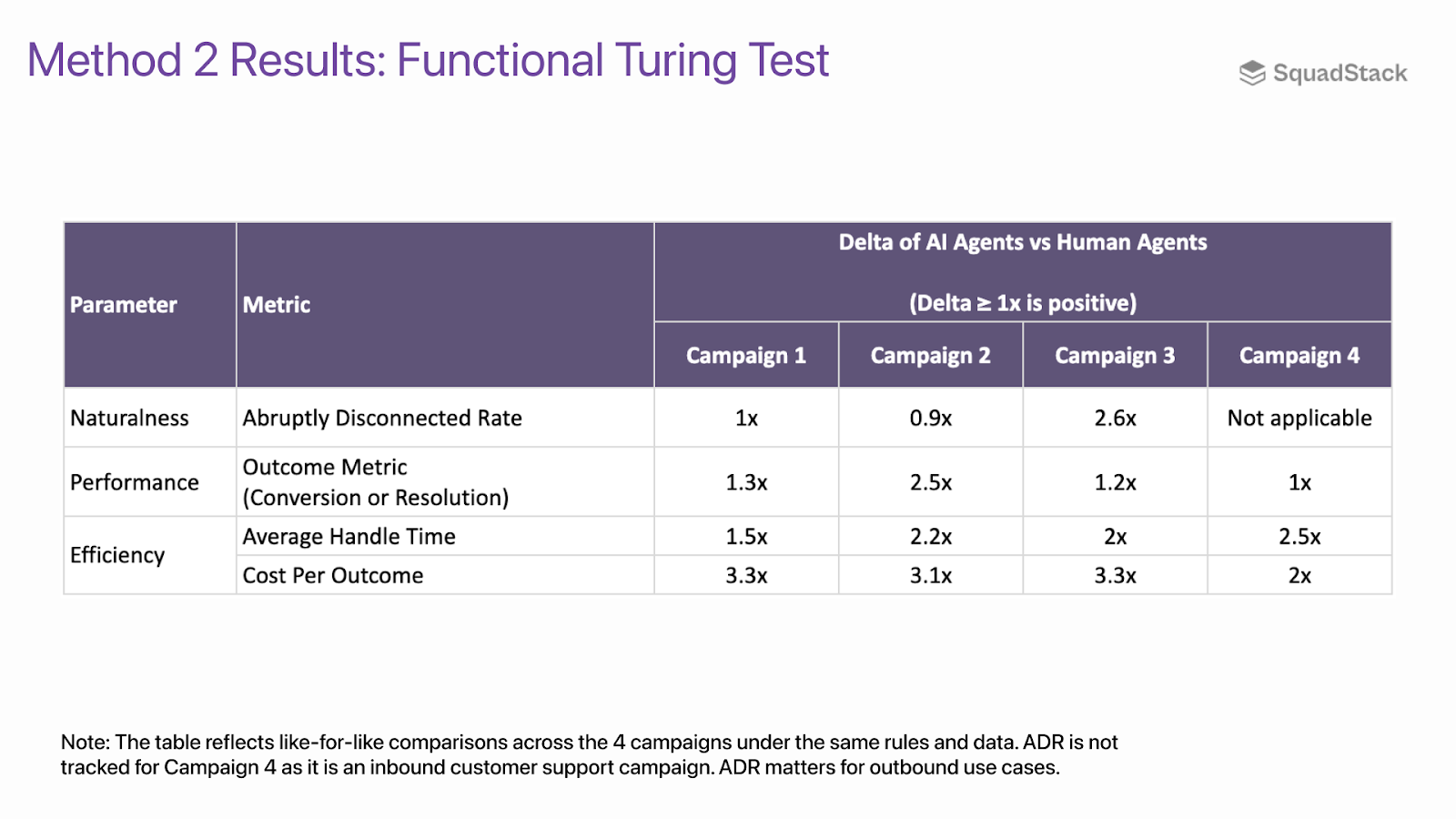
As an AI application company that owns outcomes, performance metrics are highly critical for us. An AI agent is only viable when it brings equal or better outcomes versus human contact center agents. Even if the AI agent is highly natural, it needs to deliver business outcomes to have truly “passed” the Turing test for contact centers. Performance can be measured objectively through metrics like qualification or conversion rate, containment rate, CSAT, NPS, etc.
Contact centers are often treated as big cost centers and AI agents can only pass the functional Turing test when it brings significantly better cost per outcome. Average Handle Time (AHT) is an important metric for efficiency. AHT reflects productivity, affects CAC and total cost for enterprises. If AI agents produce the same outcomes with higher AHT, it would still not be viable.
Result: Our AI agents have matched or beaten human metrics across naturalness, performance and efficiency in all 4 campaigns evaluated.
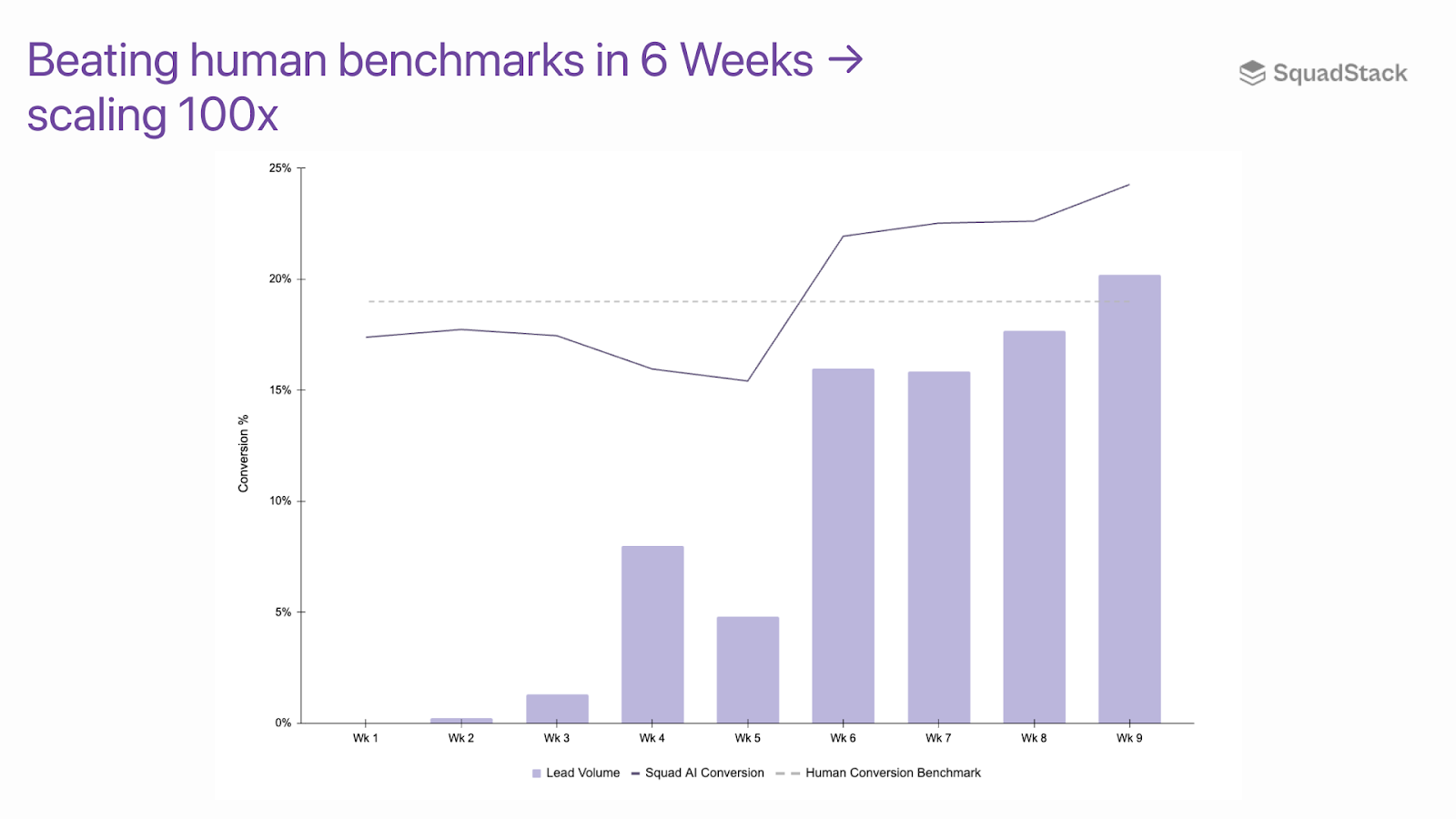
Scaling human-led contact-center campaigns is always painful - new hiring and training periods, high attrition, 2-3 months of performance drag, and higher costs until teams are stabilized. With AI agents, scaling campaigns is like scaling code: instant, consistent, and efficient. Human ramps introduce uncertainty; AI ramp ups have identical performance up to two decimal points!
Our AI and tech strategy has focused on quality and outcomes from day 1. We use a mix of in-house and third-party components optimizing for the best outcomes in each use case.
Critically, we’ve built the core voice infrastructure in-house - Speech-to-Text (STT) and Text-to-Speech (TTS) - since these are decisive for contact-center performance. Owning them gives us tight control and lets us solve complex, high-context problems.
Our AI platform at a glance:
What also sets us apart is our deep application layer - built specifically for contact-center workflows rather than being a generic AI platform. We’ve invested heavily in:
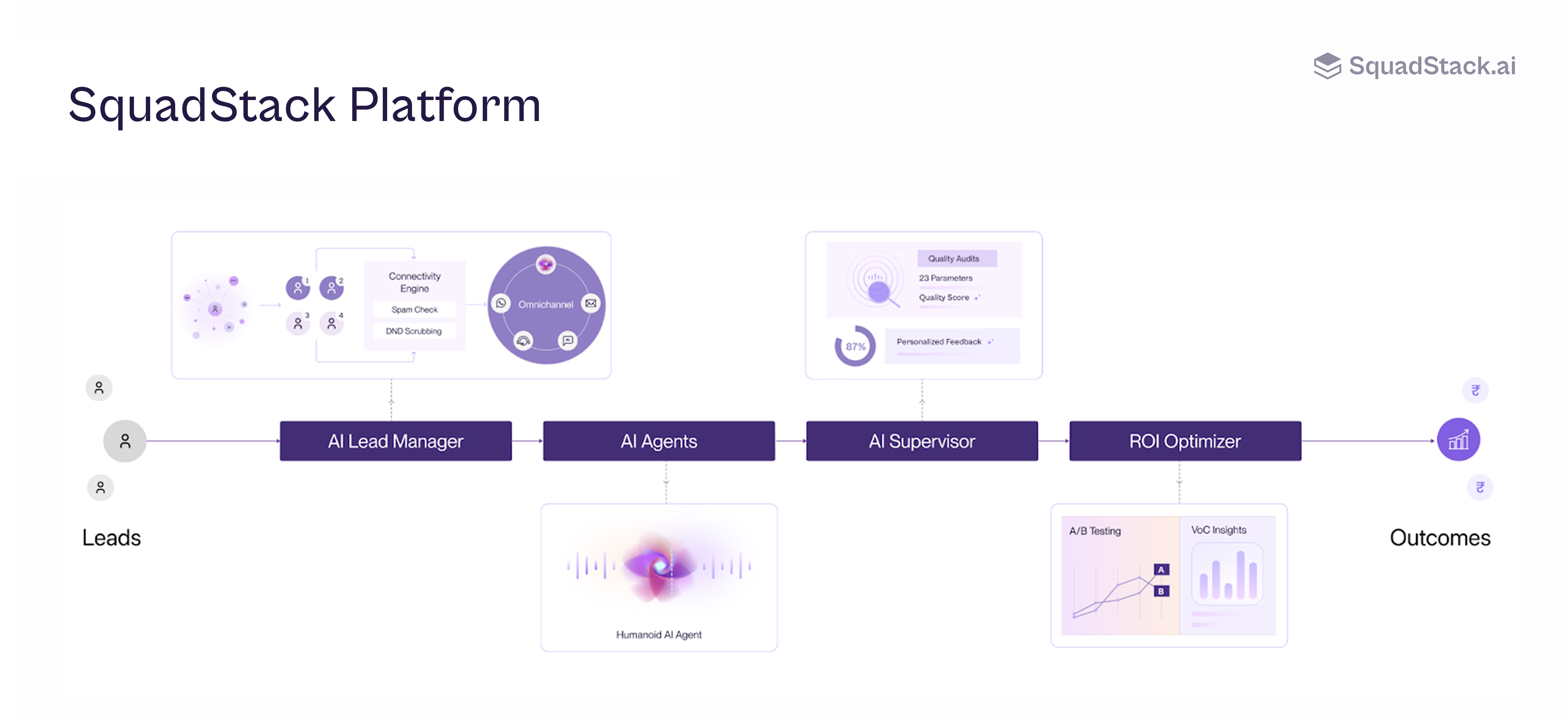
Our Platform is powered by proprietary data of Indian contact center interactions, it learns from every conversation and improves the system continuously. The result is hyper-personalized conversations that adapt to intent and context in real time. Marketing has been fully personalized over the past decade - but contact-center interactions have remained static. Our stack fixes that gap by making every touchpoint intelligent, dynamic, and data-informed.
Looking Ahead
We strongly believe that 2 things will happen:
Hence passing this Turing test in contact centers is a starting line, not a finish. Now we need to solve even more complex use cases like insurance, education, automobile, real estate and other high value sales processes end-to-end with AI agents. Today, we solve these by breaking complex journeys and distributing tasks between AI and human agents. We are already testing our next generation of AI agents with focus on dynamic rebuttals, sentiment awareness, calibrated assertiveness and even better tone & prosody control.
Our approach is to lean into the capabilities that AI agents have which aren’t possible with human agents, to deliver 10× better experiences and outcomes. One example we’re especially bullish on is hyper-personalised experiences across every channel - much like what happened in ads/marketing.


/
00:00
/
00:00
/
00:00
00:00
00:00
00:00



