






Why your voice AI leaks customer data on every sensitive call, and how we fixed it
July 9, 2026
|
4 minutes

Voice AI calls that run 20 to 45 minutes hit rising cost, growing latency, and lost context. A context management layer keeps agents fast and accurate.

The calls that actually drive revenue are long. Loan advisory, insurance claims intake, healthcare triage, education counselling, enterprise sales discovery. They run 20 to 45 minutes, carry real objections, and hinge on context built up over many turns.
For the last two years, voice AI has quietly broken on every single one of them. The experience degrades as the call stretches on, responses slow down, the agent starts missing details the caller shared earlier, and costs climb in the background at a rate that has nothing to do with how complex the conversation is and everything to do with how long it lasted.
On a short call, none of this is visible. On a longer one, three problems surface together, and each one makes the others worse.
Every time your agent responds, the system sends the entire conversation history back to the LLM. Every prior exchange, every instruction, is rebuilt and resent from the top.
On a three-minute call, the payload is small and cheap. On a thirty-minute call, that payload has been rebuilt sixty times, each time larger than the last. Your per-turn cost doesn't grow with call length. It grows closer to the square of it, because every new turn carries the accumulated weight of all prior turns inside it.
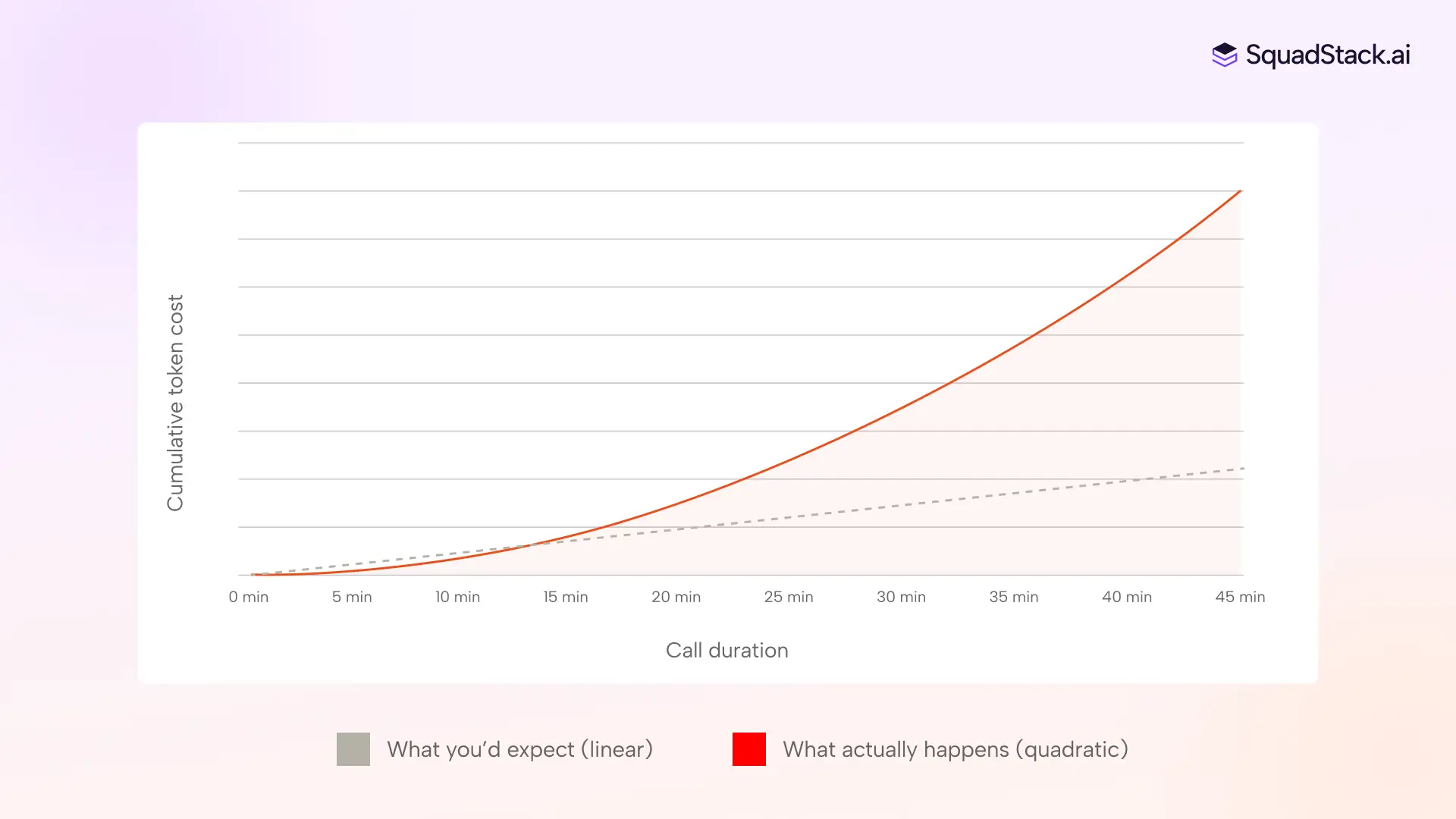
If you're running long-form use cases at volume, like loan advisory, account opening, healthcare intake, or claims processing, this cost curve quietly makes unit economics unsustainable without anything changing about the product itself. And the calls that used to drop halfway through, or fall apart before closing, weren't just expensive. They were costing you the deal.
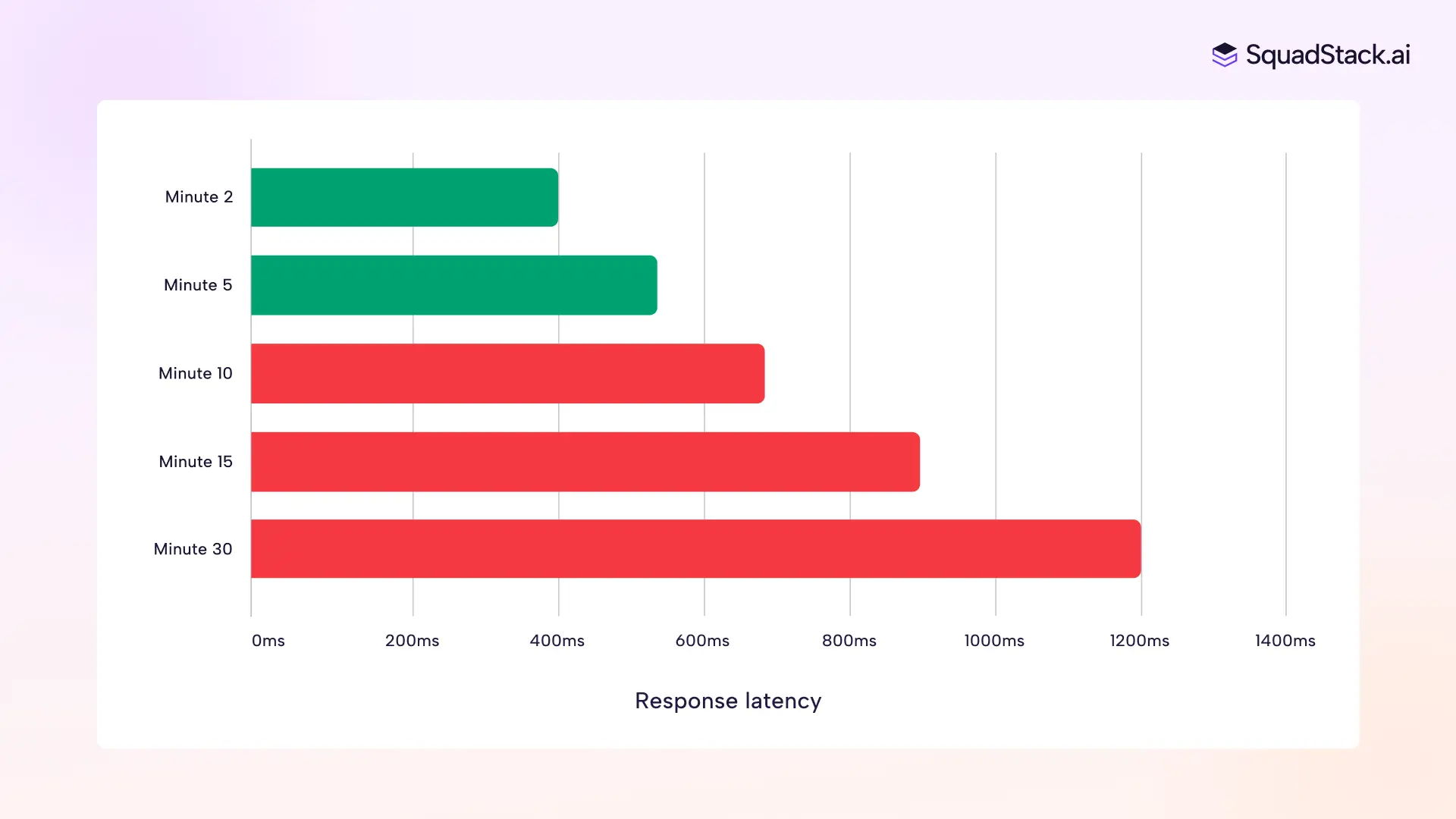
More tokens in means slower inference out. The model takes longer to process, and the gap between the caller finishing their sentence and the bot responding gets wider. In a text interface, an extra second of processing is barely noticeable. In a voice conversation, a few hundred milliseconds can break the rhythm of natural speech.
A bot that responds in 400ms at minute two and 1.2 seconds at minute fifteen does not feel like the same bot. The caller notices, even if they cannot articulate why.
Language models attend unevenly to long inputs. Information near the beginning and end of the context window gets the most weight, while facts in the middle are progressively ignored.
On a short call, everything stays within the model's zone of strong attention. On a long one, the budget your caller mentioned ten minutes ago sits in exactly the part of the window where the model is least reliable. The caller has to correct the bot, trust erodes, and the conversation takes longer, which feeds back into the cost and latency problems above.
These three issues do not simply coexist. They form a cycle. Cost pressure pushes teams toward smaller, cheaper models. Smaller models are more sensitive to noisy context. Noisier context means worse accuracy and longer calls. Longer calls mean higher costs. The more ambitious the use case, the faster this cycle spins.
.webp)
The fix is not a bigger context window or a better model. It is a layer that sits between the conversation engine and the language model, assembling exactly what the model needs for each turn.
Think of it as a briefing note your agent writes to itself before every turn. Instead of rereading the entire conversation from the top, it checks a short summary of what happened, the key facts already collected, and the last few exchanges. That's all the model sees.
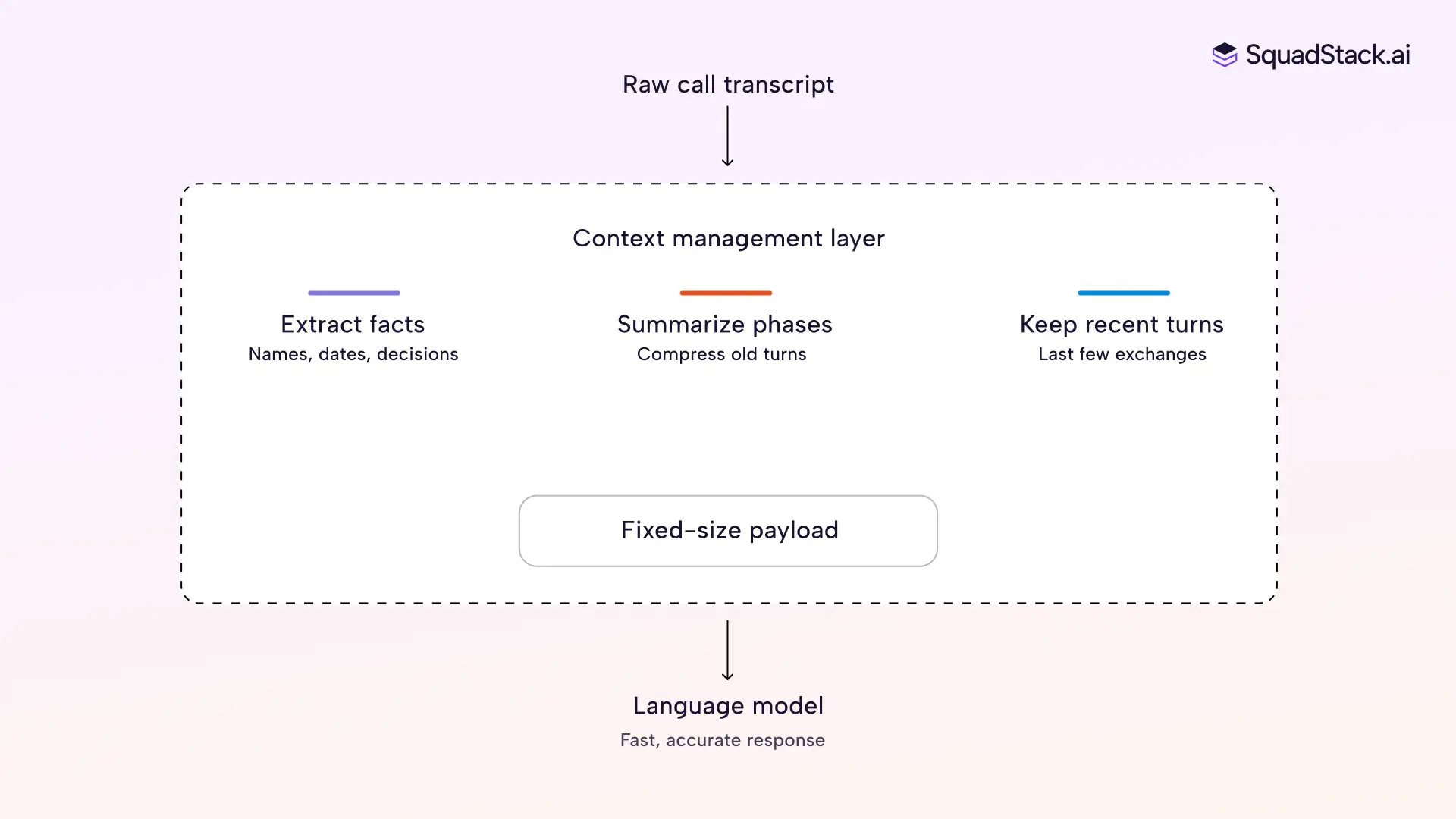
This layer does three things as your conversation moves forward.
The result is a context payload that stays roughly the same size whether your call is five minutes old or forty-five. At minute thirty of an insurance claim, your model responds just as fast as it did at minute two, and still knows the caller's policy number, claim date, and damage description, because those facts sit in clean structured fields rather than somewhere deep inside a growing transcript.
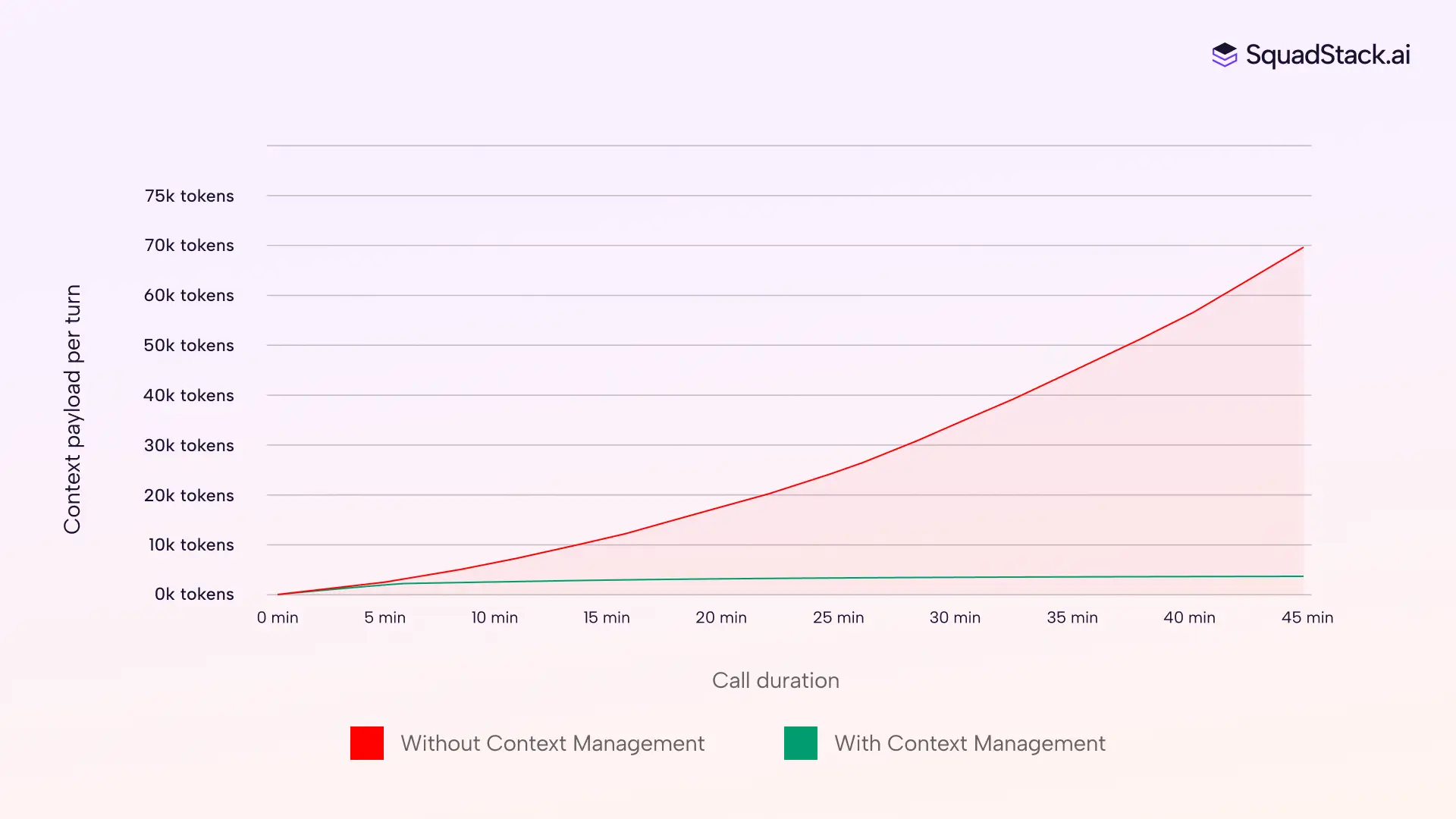
You can also set a hard ceiling on tokens per turn. If the conversation runs long and the assembled context gets heavy, the layer compresses the oldest summaries first, then trims turn history. Your agent at minute twenty stays within the same token budget it had at minute three, so you always know what it costs and what the model is working with.
Different parts of a call can also route to different models. When your agent is collecting a name, date of birth, and address, a lighter model handles that fine. When the caller pushes back on pricing or asks something that needs real reasoning, that turn routes to a more capable model. The context layer formats the right payload for whichever model is active, so your team decides the routing logic and the layer takes care of the rest.
Context management solves the problem within a single call. Across calls, the gap takes a different shape. Your agent handles a detailed conversation, collects everything it needs, and then has no way to use any of it when the same person calls back. We wrote about this problem and how we approach it in our Persistent Memory deep dive.
What matters here is how in-call context and cross-call memory connect. The same structured data your context layer extracts during a call, the facts, decisions, and outcomes, becomes the memory record that persists after the call ends. When that caller returns, the agent loads this record before the conversation starts, so it picks up with awareness rather than a blank slate.
This memory also has to age honestly. A phone number from last week is probably still good, but an address from eighteen months ago might not be. The agent flags older data for confirmation rather than treating it as current fact, which is the difference between feeling remembered and feeling assumed about.
The part of the voice AI stack that has improved the least is the one that affects every call the most, how much context your model carries on each turn. Cost, speed, and accuracy all trace back to it.
For teams whose revenue sits inside 20-minute conversations, that's the layer worth fixing first.



